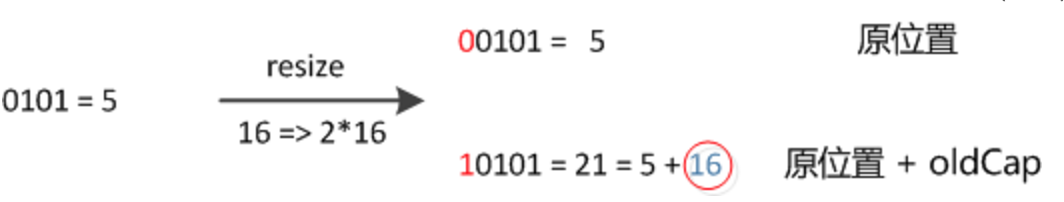![Map]()
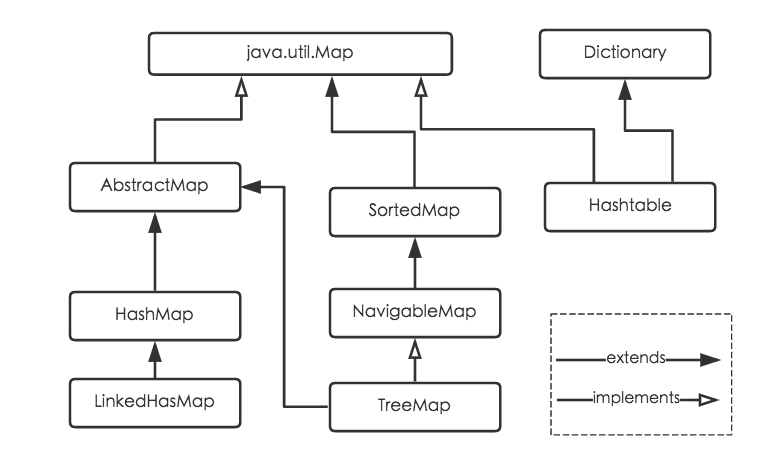
前面了解了哈希表,hashmap的原理就是哈希表。hashmap散列函数采用取余法,冲突解决采用的是链地址法。
概述
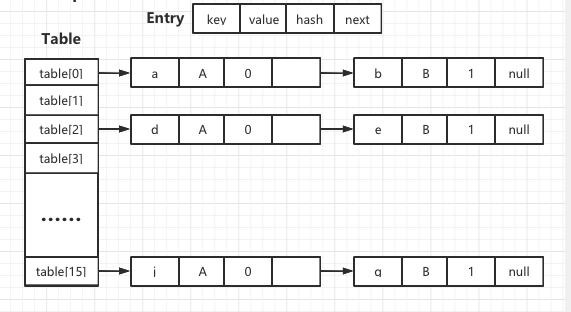
本文基于jdk1.8,HashMap中,键值对(key-value)在内部是以Entry(HashMap中的静态内部类)实例的方式存储,散列表table是一个Entry数组,保存Entry实例。如果若干个entry计算得到相同散列地址(具体是由(n-1)&h(key)求得),这些entry被组织成一个链表,并以table[i]为头指针。
![hashMap结构]()
函数
1
2
3
4
5
6
| static final int hash(Object key) {
// h = key.hashCode() 为第一步 取hashCode值
// h ^ (h >>> 16) 为第二步 高位参与运算
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
|
由于采用以上两个函数,哈系表的长度lenth大小必须是2的n次方(一定是合数),这是一种非常规的设计,常规的设计是把表的长度设计为素数。目的在于 在取模和扩容时做优化,减少冲突,定位哈希表索引位置时也加入了高位参与运算的过程(非合数设计缺陷的补偿)。
Jdk1.8版本中,对数据结构做了进一步优化,引入红黑树。而当链表长度太长时(默认超过8)。链表就会转换为红黑树,利用红黑树快速增删改查的特点提高hashmap的性能;
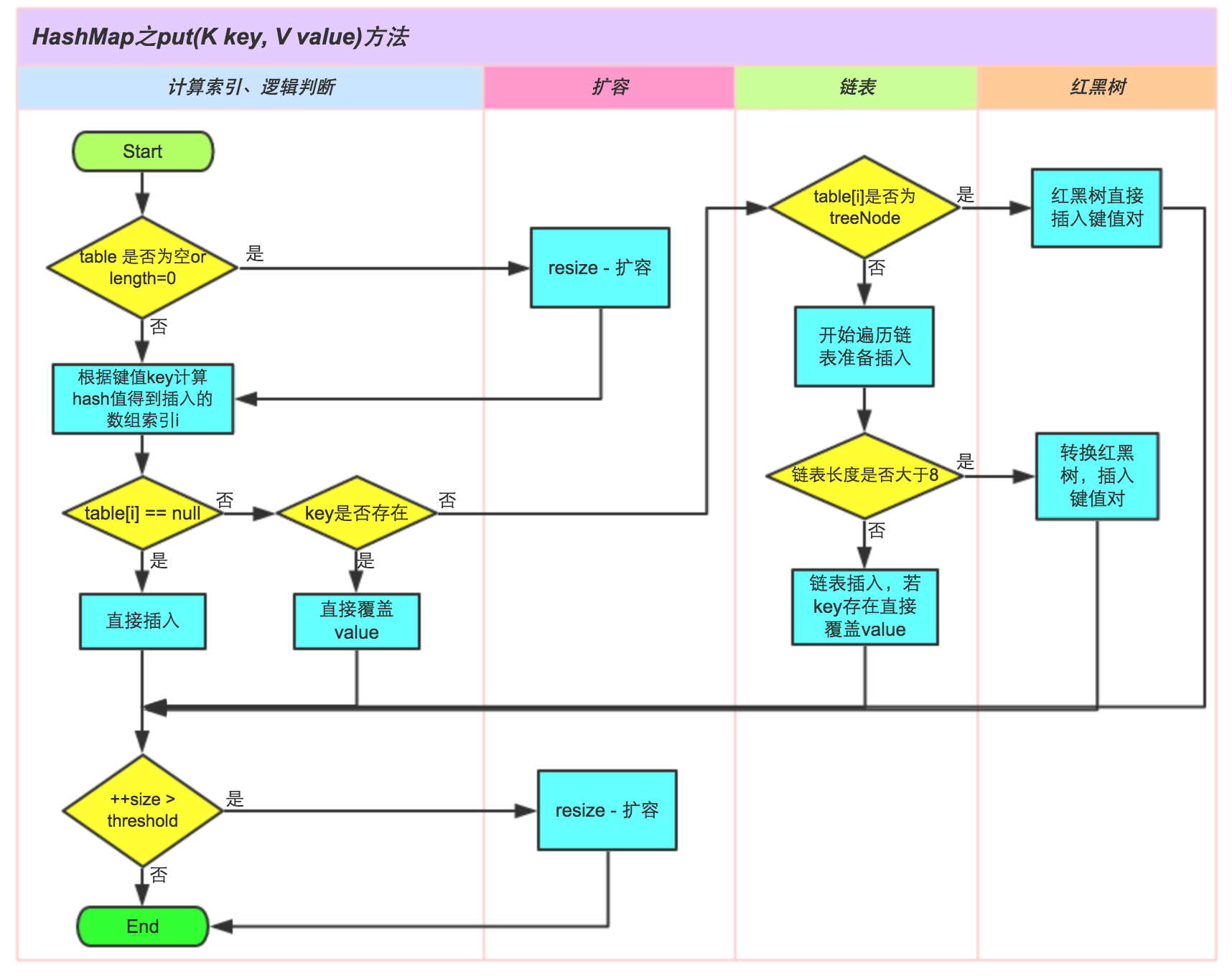
分析HashMap的put方法
![]()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//1、table不存在、或长度=0 ,resize。
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//2、获取对应位置node,为null时 直接将新node存入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//3、对应位置的node不是null,且key相等 直接赋值;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//4、key 不相等、但 node 是 treenode,直接封装为treenode存入链中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//5、key不相等、node是普通的node,直接遍历存入链未。
for (int binCount = 0; ; ++binCount) {
//6、到队尾未找到相等元素,将新元素存入队尾。
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//8、存入后链中node数大于临界值(8),将普通node链转换为红黑树。
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//7、找到相等key值,直接将新node替换老node
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//9、已经存在的key,返回之前的value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//10、超过指定容量,进行resize。
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
|
扩容
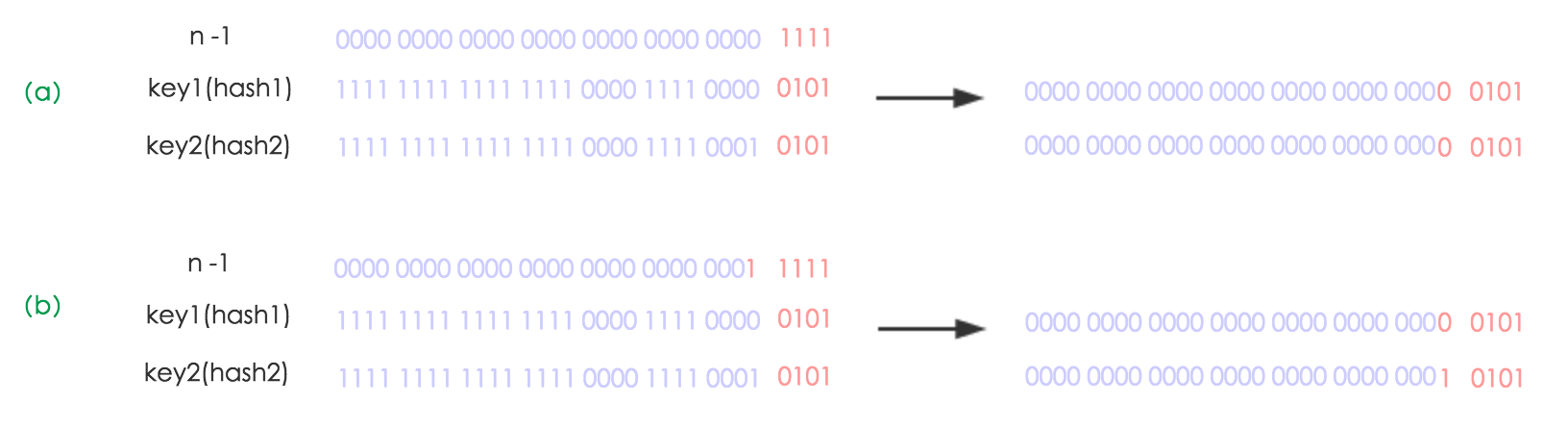
扩容(resize)就是,原有容量不够使用后将容量扩大。table长度变大以后,移动entry位置是很讲究的。最笨的方式就是遍历所有的node,重新计算hash,取模值,放入对应位置。但JDK1.8做了一些优化:
![]()
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
![]()
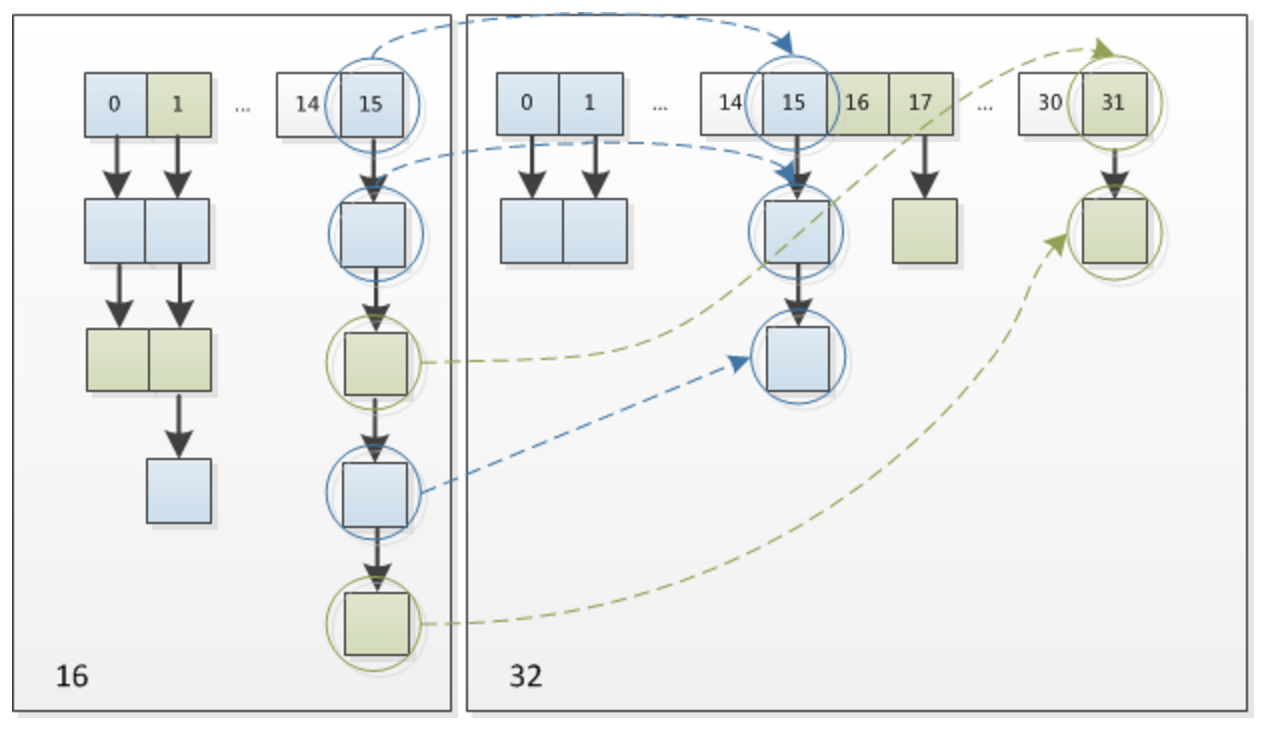
因此,我们在扩充hashmap的时候不需要向JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是0还是1就好了,是0的话索引没有变化,是1的话索引变成了“元索引+oldCap"可以看看16扩充到32的resize示意图:
![]()
这个设计非常的巧妙,即省去了重新计算hash值得时间,而且可以把之前冲突的节点均匀的分散到新的bucket上。
备注:jdk7在rehash的时候如果在新链表的数组索引位置相同,则链表元素会倒置,JDK8是不会的。
安全
Hashmap是线程不安全的,涉及多线程时使用ConcurrentHashMap代替。
参考阅读